[Paper Review] SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization 정리
in Machine Learning on Paper Review
본 포스트는 SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization, CVPR, 2020을 정리한 글입니다.
Introduction
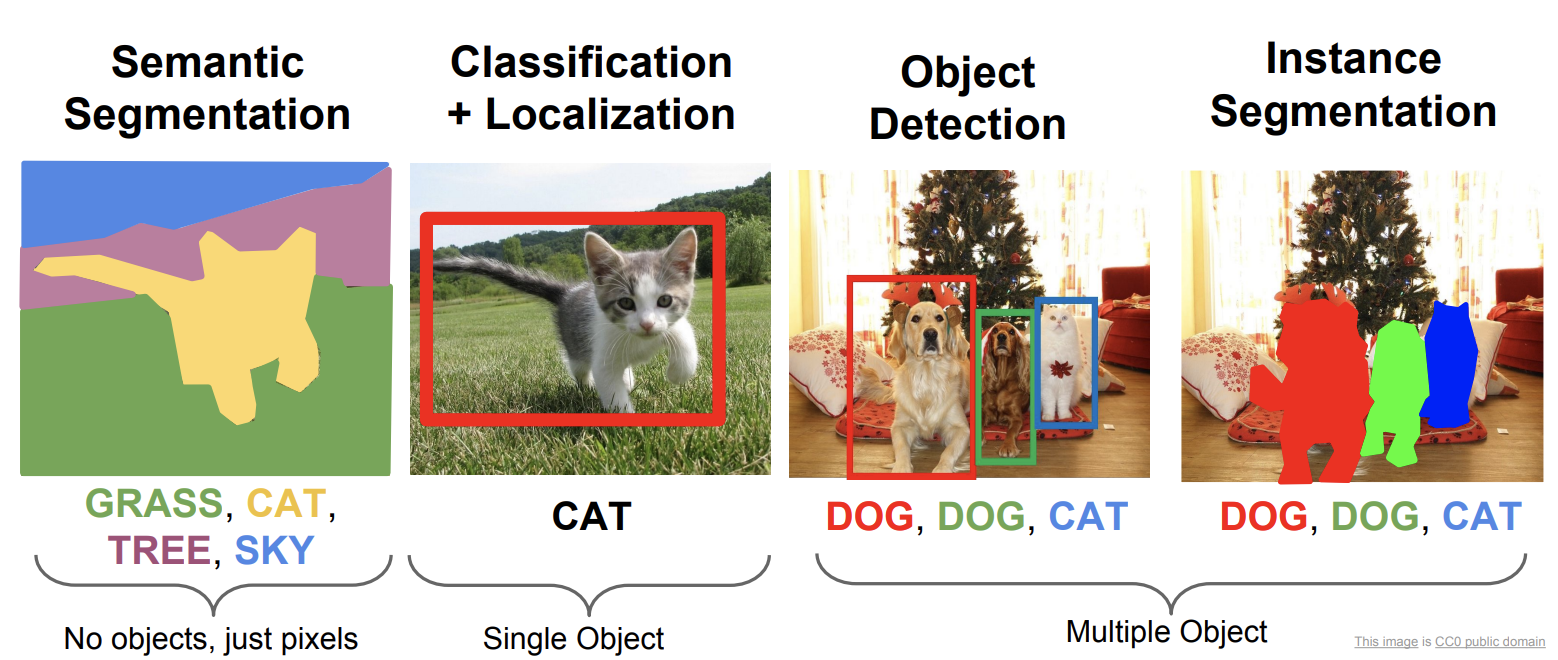
Object Detection/Instance Segmentaiton와 같은 Computer Vision Task에서 Backbone Network로 주로 ImageNet Pretrained Model을 사용합니다. ImageNet Pretrained Network는 Stage를 통해서 점차 Feature map의 크기는 줄여나가고 채널 수는 늘려가면서 Input 이미지에서 분류를 위한 중요한 Feature들을 추출해냅니다.
그에 반해서 Object Detection/Instance Segmentaiton에서는 여러 물체들의 위치를 찾고 분류를 동시에 수행하기 때문에 분류를 위한 Feature외에 위치 정보를 위한 Feature들 또한 요구됩니다. 그러나 대부분의 경우 Backbone으로 분류 모델을 사용하며 위치정보를 제대로 추출해내지 못하는 모델을 사용합니다.
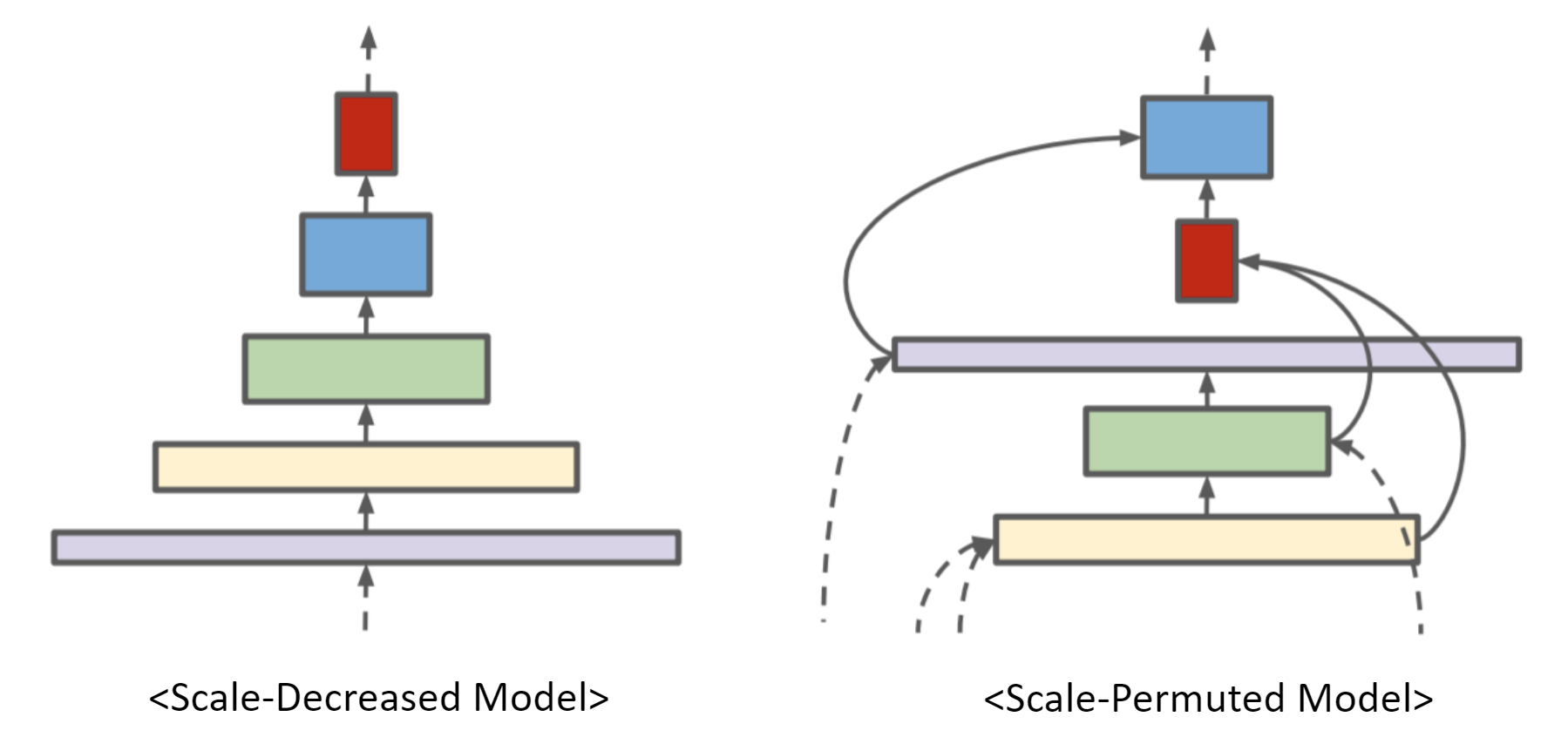
이 논문에서는 “Input 이미지의 Scale을 줄여나가는 Scale-Decreased Model이 Object의 정확한 위치 정보를 필요로하는 Task들(e.g. Object Detection/Instance Segmentation)에 적합한가?” 라는 Motivation을 가지고 실험을 진행하며, Recognition과 Localization(=Multi-Scale Features)에 더 적합한 Scale-Permuted Model를 제안합니다.
Method
Scale Permuted Method
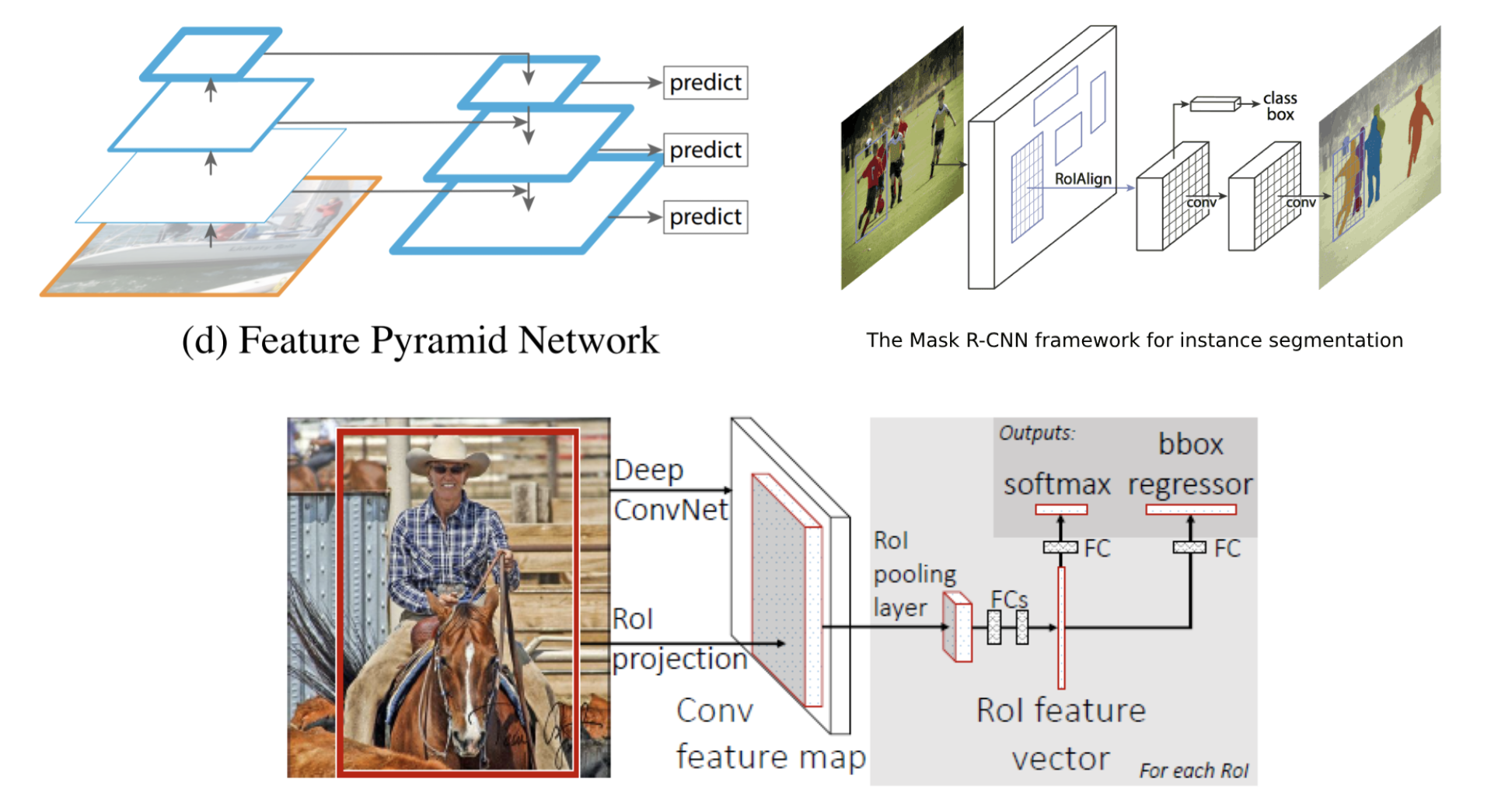
논문에서 제안하는 Backbone은 고정된 Stem network와 NAS를 통해 학습되는 Scale-Permuted network로 구성됩니다.
FPN처럼 여러 스케일의 Mulit-Scale Fetarures를 Output으로 받기 위해 5개의 Output block을 미리 지정합니다. 5개의 Output Scale(\(L_3\), \(L_4\), \(L_5\), \(L_6\), \(L_7\))을 미리 정하고 그 블록들은 Backbone의 head 부분에 위치합니다.(위 그림에서 빨간 테두리의 block) \[L_n : \frac{1}{2^n} \times input \; resolution\]
ResNet50은 \(L_6\)과 \(L_7\) Scale Block이 없기 때문에 하나의 \(L_5\) 블록을 \(L_6\)과 \(L_7\) 블록 각각 한 개로 바꿔줍니다.
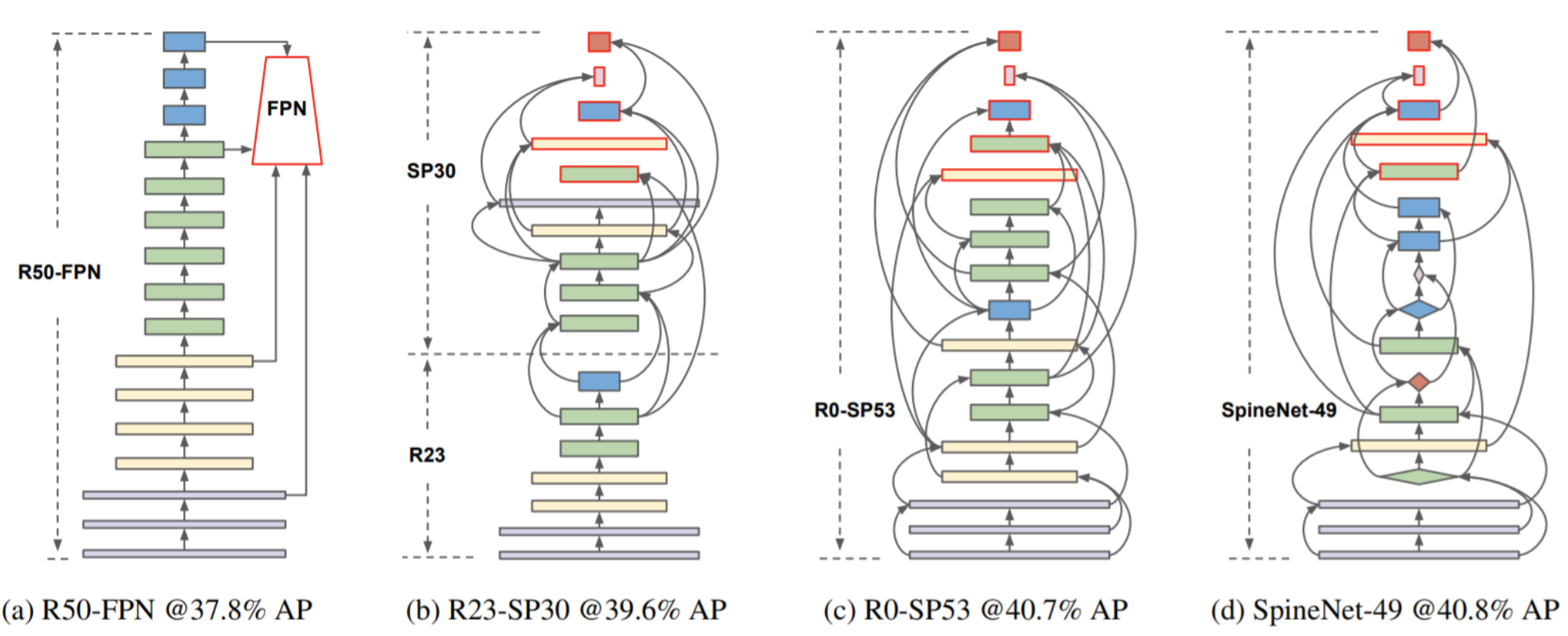
1-stage Dectector 중 Backbone으로 ResNet50을 사용하는 RetinaNet(a)을 Baseline으로 하고 강화학습기반 NAS(Neural Architecture Search)로 (1) Scale Permutation, (2) Cross-Scale Connections을 찾고 추가적인 (3) Block Adjustment를 통해 Scale-Permuted Model인 SpineNet을 찾습니다.
Search Space
Search Space는 아래와 같은 3가지로 구성됩니다.
Scale Permutations
앞의 Block으로부터만 연결될 수 있으므로 어떻게 Scale Permutation이 되는지는 중요합니다. 고정된 5개의 Output Block은 Head에 위치되어야 하기 때문에 \(5!\)의 Search Space Size와 나머지 블록들의 Permutation인 \((N-5)!\)의 Search Space 크기는 총 \(5!(N-5)!\)를 가지게 됩니다.Cross-Scale Connections
앞 쪽의 2개의 블록으로부터 Input을 받고, 다른 Scale의 Feature를 받을 수 있으므로 Resampling 과정을 거치게 됩니다. Resampling 과정은 아래 Resampling in Cross-Scale Connection에서 자세히 설명합니다. Search Space 크기는 \(\Pi_{i=m}^{N+m-1}C_2^i\)가 됩니다. 여기서 \(m\)은 stem network에서 선택 가능한 Block의 갯수입니다.Block Adjustments
Output Block을 제외한 Intermediate Block은 Scale level을 변경할 수 있고 Output Block을 포함한 모든 Block은 Block Type을 변경할 수 있습니다. Scale Level은 {-1, 0, 1, 2}로 줄이거나 유지하거나 늘리는 방법으로 변경 가능하고 Block Type은 {Bottleneck, Residual}로 변경 가능합니다. Search Space 크기는 \(4^{N-5}2^N\)가 됩니다.
Resampling in Cross-Scale Connection
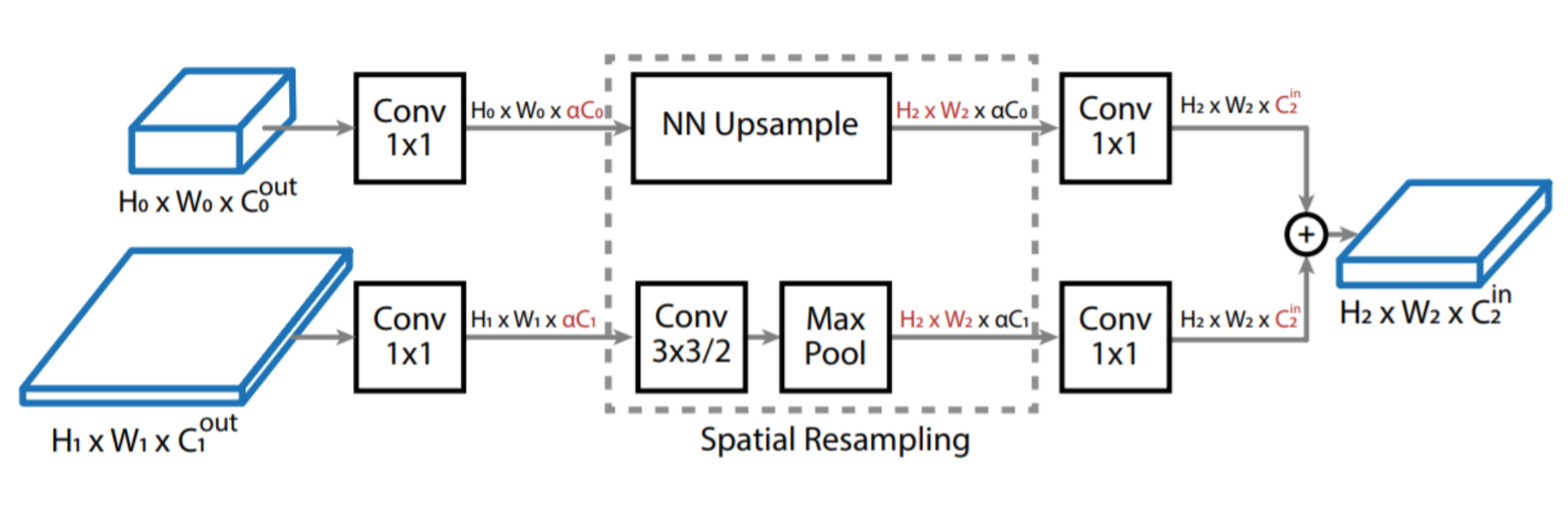
ResNet50과 Computation Cost를 같게 유지하기 위해 Scaling Factor \(\alpha\)(0.5, default)를 사용하여 1x1 Conv의 채널 수를 Scaling합니다. Up-sampling은 NN(Nearest-Neighbor) Interpolation을 통해 Feature Map Scale을 늘려주며, Down-sampling 과정은 stride 2의 3x3 Conv와 Maxpooling을 사용하여 Feature map을 줄여줍니다. 이후 Element-wise Addition을 통해서 두 Feature map을 더해줍니다.
NAS Detail
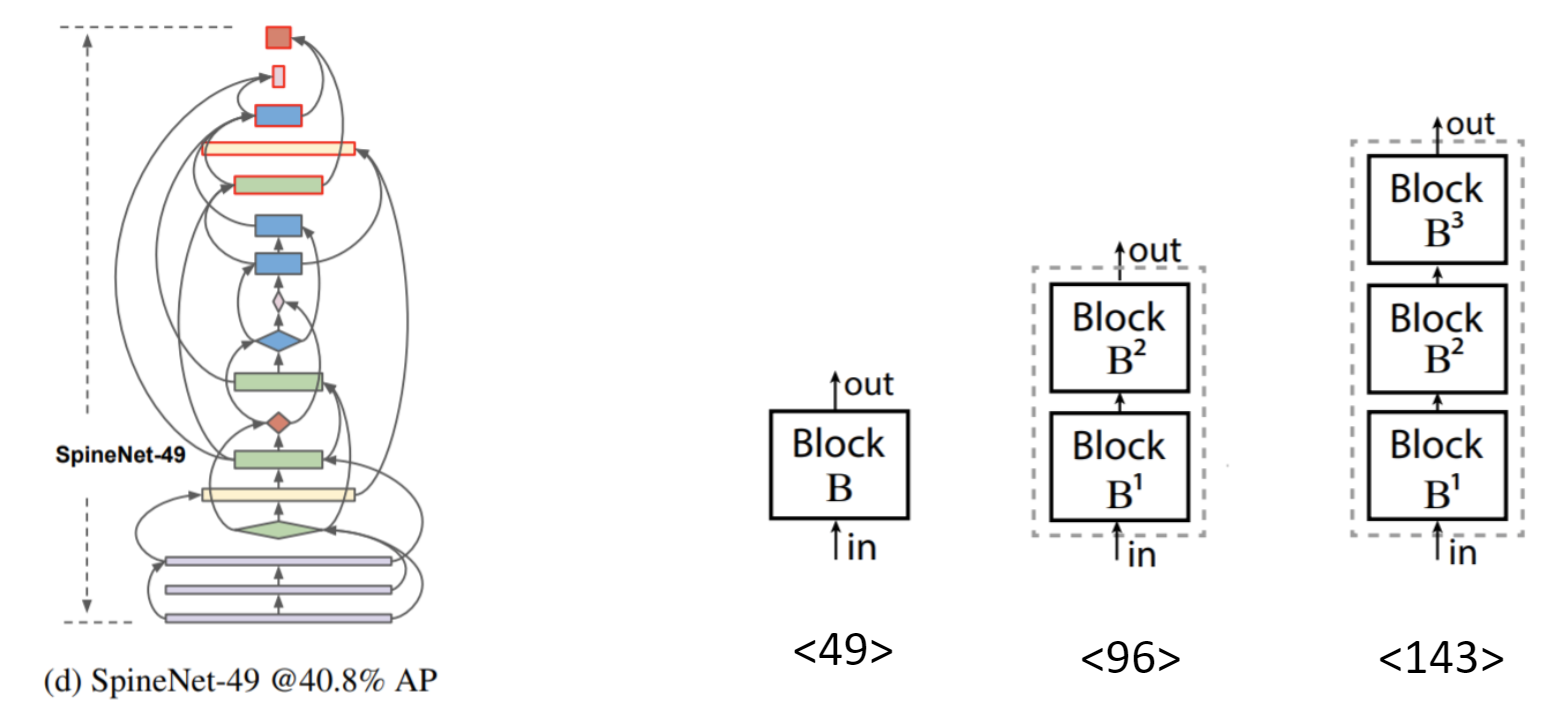
NAS-RL의 방식을 이용해 RNN based Controller로 Architecture를 얻습니다. 위에서 정의한 Search Space도 사이즈와 계산량이 매우 크기 때문에 Feature dimension과 Scaling Factor를 줄이고 Intermediate block의 Parent를 최근 5개로 줄이는 등 더 좁은 Search Space 내에서 Proxy SpineNet을 찾습니다.
512x512 resolution으로 5epoch를 Train하고 Validation AP를 Reward로 하여 학습을 진행하고, 이렇게 하여 찾은 모델이 SpineNet-49이고 더 큰 모델 같은 경우는 그림과 같이 하나의 블록 안을 여러 개의 블록으로 늘리거나 Feature Dimension의 크기를 키워서 큰 모델을 얻습니다. SpineNet-96은 블록 안에 2개의 블록 SpineNet-143은 3개의 블록과 같은 방법으로 더 큰 SpineNet을 얻습니다.
Experiments
One-Stage Object Detection Results on COCO test-dev
 COCO test-dev set에서 1-stage Detector RetinaNet의 결과입니다. SpineNet을 Backbone으로 사용한 RetinaNet은 ResNet50을 Backbone으로 사용한 RetinaNet보다 더 적거나 같은 #Param과 #FLOPs를 가지고 더 좋은 성능을 보여줍니다. 아래 쪽의 dagger(†) 표시된 결과들은 ReLU를 Swish로 바꾸고 Stochasic Depth Training과 함께 더 긴 epoch로 트레이닝한 결과이며 더 좋은 성능을 보입니다.
COCO test-dev set에서 1-stage Detector RetinaNet의 결과입니다. SpineNet을 Backbone으로 사용한 RetinaNet은 ResNet50을 Backbone으로 사용한 RetinaNet보다 더 적거나 같은 #Param과 #FLOPs를 가지고 더 좋은 성능을 보여줍니다. 아래 쪽의 dagger(†) 표시된 결과들은 ReLU를 Swish로 바꾸고 Stochasic Depth Training과 함께 더 긴 epoch로 트레이닝한 결과이며 더 좋은 성능을 보입니다.
Two-Stage Object Detection and Instance Segmentation Results on COCO
 2-stage Detector인 Mask R-CNN에서 Object Detection과 Instance Segmentation의 결과입니다. 1-stage Detector의 결과와 마찬가지로 더 나은 성능을 보여줍니다. RetinaNet에서 Train된 Backbone을 Mask R-CNN에 그대로 활용한 결과이지만 더 나은 결과를 보이고 있습니다.
2-stage Detector인 Mask R-CNN에서 Object Detection과 Instance Segmentation의 결과입니다. 1-stage Detector의 결과와 마찬가지로 더 나은 성능을 보여줍니다. RetinaNet에서 Train된 Backbone을 Mask R-CNN에 그대로 활용한 결과이지만 더 나은 결과를 보이고 있습니다.
Ablation Study for Scale Permutation
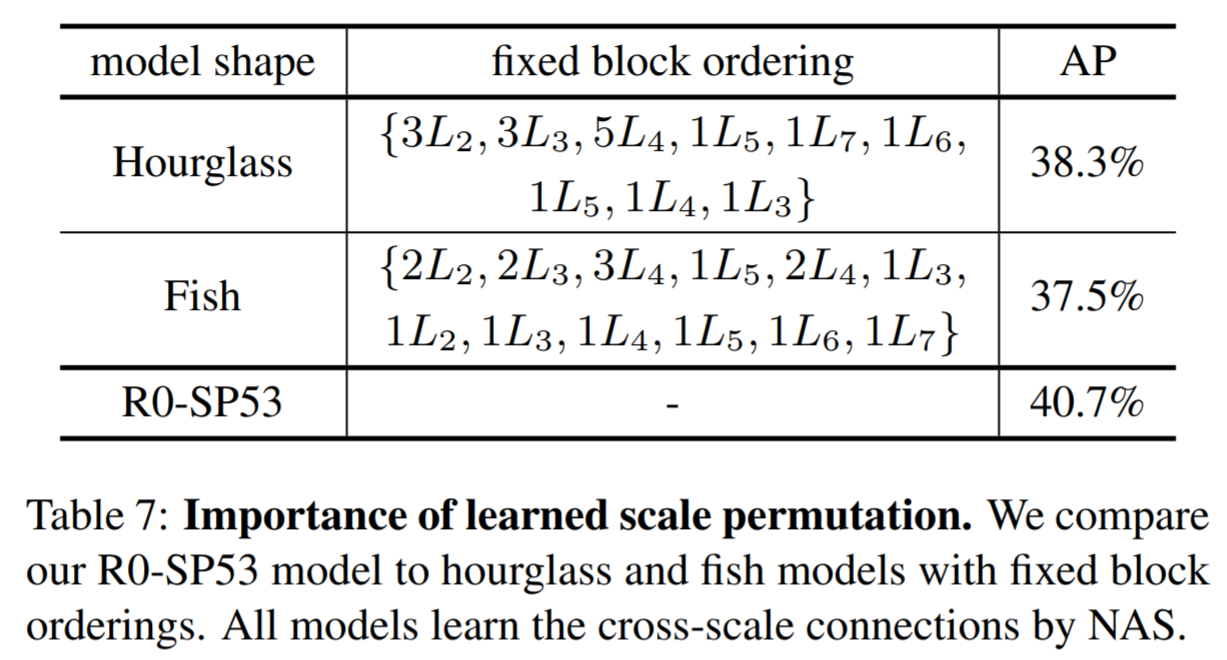 Encoder-Decoder 형태인 Hourglass와 FishNet의 형태로 Block 순서를 고정한 모델을 만들고 SpineNet과 마찬가지로 Cross-Connection은 학습을 통해 배우게 하며, Scale Permutation이 얼마나 효과적인지 실험한 결과입니다.
Encoder-Decoder 형태인 Hourglass와 FishNet의 형태로 Block 순서를 고정한 모델을 만들고 SpineNet과 마찬가지로 Cross-Connection은 학습을 통해 배우게 하며, Scale Permutation이 얼마나 효과적인지 실험한 결과입니다.
Ablation Study for Cross-Scale Connections
 학습을 통해 연결된 Cross-Connection이 얼마나 중요한지에 대한 Ablation Study입니다. 짧은 Connection보다 긴 Connection이 더 Critical하다는 것을 알 수 있습니다.
학습을 통해 연결된 Cross-Connection이 얼마나 중요한지에 대한 Ablation Study입니다. 짧은 Connection보다 긴 Connection이 더 Critical하다는 것을 알 수 있습니다.
Image Classification Result on ImageNet and iNaturalist
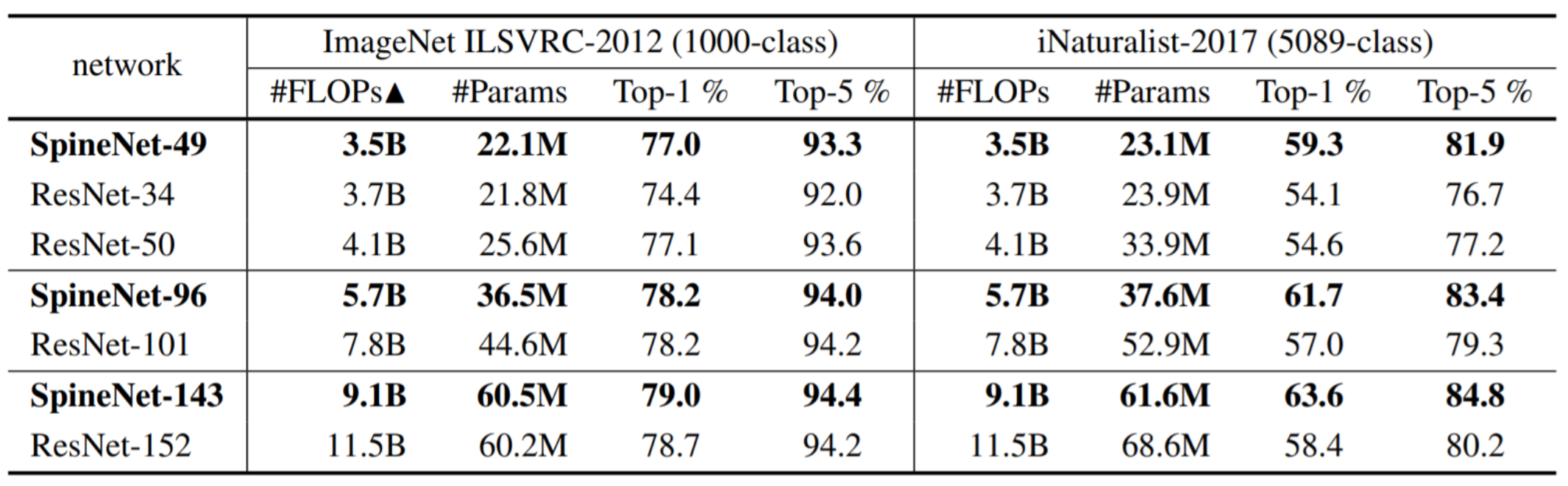 ImageNet과 iNaturalist라는 Classification Task에 대한 실험 결과입니다. ImageNet에서는 더 적거나 같은 #Param과 #FLOPs를 가지고 비슷한 성능을 보여줍니다. 이후 실험에서 Activation을 Swish로 변경하고 Stochasic Depth Training 등을 통해 더 좋은 성능을 보여줬다고 합니다.
ImageNet과 iNaturalist라는 Classification Task에 대한 실험 결과입니다. ImageNet에서는 더 적거나 같은 #Param과 #FLOPs를 가지고 비슷한 성능을 보여줍니다. 이후 실험에서 Activation을 Swish로 변경하고 Stochasic Depth Training 등을 통해 더 좋은 성능을 보여줬다고 합니다.
iNaturalist Dataset은 5089개의 클래스를 가지는 자연 생물들의 대한 Dataset입니다. iNaturalist Dataset에서는 ResNet보다 더 좋은 성능을 보였습니다. 저자들은 이 이유를 Scale-Decreased model보다 SpineNet이 Local Difference를 더 잘 포착하고 더 Compact한 Feature Representation으로 더 잘 학습할 수 있었다고 분석하고 있습니다.
Reference
CS231n
Feature Pyramid Network for Object Detection
Faster R-CNN
Mask R-CNN
SpineNet: Learning Scale-Permuted Backbone for Recognition and Localization
이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)

