앙상블(Ensemble) 기법 정리
in Machine Learning on Basics
이 글은 앙상블 학습 (Ensemble Learning)에 대해 정리한 글 입니다.
앙상블 학습 (Ensemble Learning)
- 여러 단일 모델들을 하나로 엮어 더 좋은 성능을 내는 복합 모델을 만드는 것.
- Several weak learners are better than one strong learner.
- 현실로 예를 들면, 한 명의 전문가 보다 여러 명의 집단 지성이 더 낫다. (wisdom of the crowd)
- 하나의 모델을 사용할 때보다 더 일반화된(Generalized) Model을 얻을 수 있음.
- Kaggle 등과 같은 Competition 들에서 항상 사용.
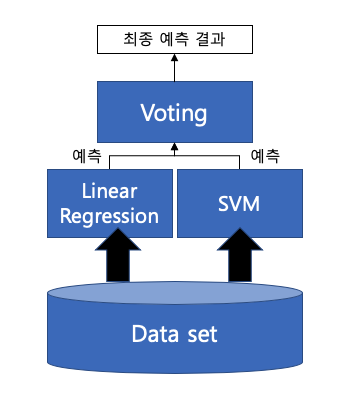
Voting
- 여러 개의 Classifier가 Vote(투표)를 통해 결정
- 보통 서로 다른 알고리즘(Classifier)을 여러 개 결합하여 사용
- 다른 모델이 만들어내는 다른 종류의 오차 분포로 인해 앙상블 모델 정확도는 상승
- e.g.) SVM + Linear Regression
- Voting(투표) 방식
- Soft-Voting : Classifier의 확률 값을 평균을 내서 확률이 가장 높은 레이블로 결정
- Hard-Voting : 각 Classifier가 예측한 결과값(Label)으로 투표해서 가장 투표 수가 많은 레이블로 결정
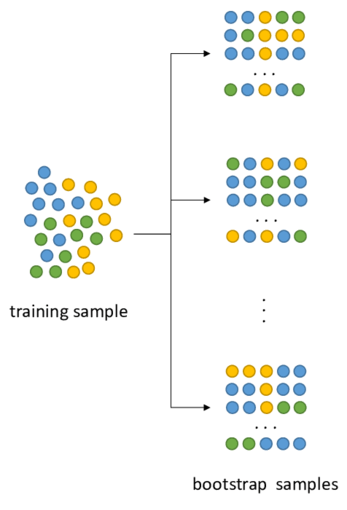
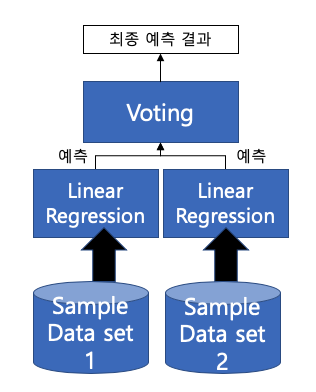
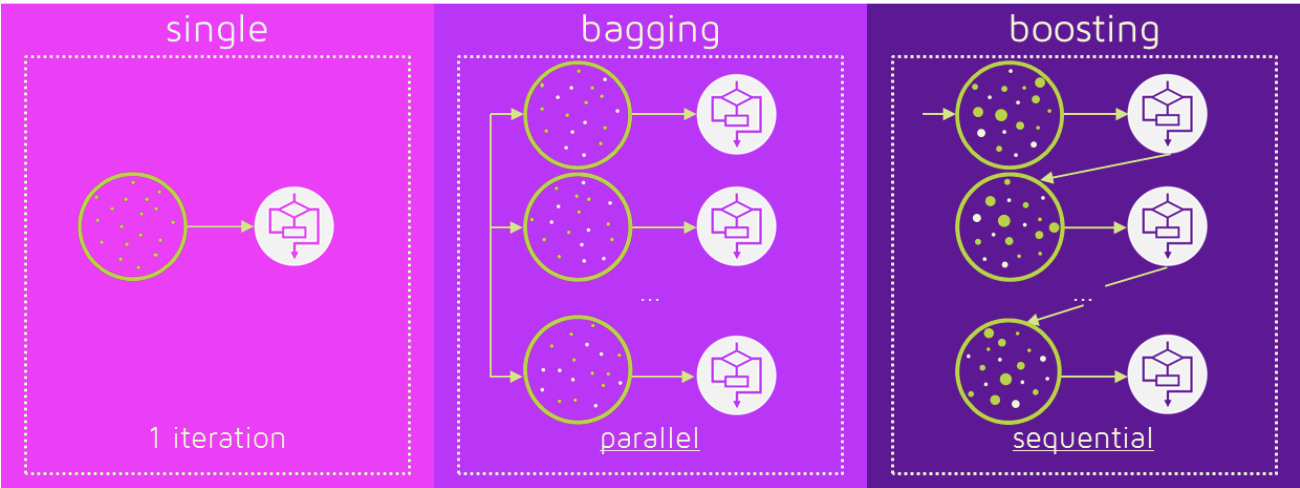
Bagging (Bootstrap + Aggregating)
- Bootstrap(중복 허용 재추출)을 통해 모델을 학습시키고 결과를 집계(Aggregating) 하는 방법
- *Pasting : 중복 비허용 추출 + Aggregating
- 보통 모두 같은 유형의 알고리즘 기반의 분류기를 사용
- Overfitting 방지에 효과적
- Model Variance 감소
- 집계(Aggregate) 방식
- Categorical Data (Classification) : 다수결 투표 방식으로 결과 집계
- Continuous Data (Regression) : 평균값 집계
- 대표적인 방식 : Random Forest (= Bagging with Decision Tree)
 |  |
Boosting
- 여러 개의 분류기가 순차적(Sequential)으로 학습을 수행
- 이전 분류기가 예측이 틀린 데이터에 대해서 올바르게 예측할 수 있도록 다음 분류기에게 가중치(weight)를 부여하면서 학습과 예측을 진행
- 오답에 정답보다 더 높은 Weight를 부여해서 오답에 집중
- 계속하여 분류기에게 가중치를 부스팅하며 학습을 진행하기에 부스팅 방식이라고 불림
- 예측 성능이 뛰어나 앙상블 학습을 주도
- 대표적인 부스팅 모듈 – AdaBoost, GradientBoosting, XGBoost, LightGBM
- 보통 부스팅 방식은 배깅에 비해 성능이 좋지만, 속도가 느리고 과적합이 발생할 가능성이 존재
- Outlier에 취약할 수 있음.
Stacking
- Stacked Generalization 이라고도 함.
- Weak Learner들의 예측 결과를 바탕으로 Meta Learner(또는 Blender)를 학습시켜 최종 예측값을 결정
- Voting에서 aggregation하는 function을 학습하는 느낌
- Voting에서 사용한 간단한 함수를 사용하는 대신에 prediction을 취합해서 prediction을 하는 Meta Learner를 학습
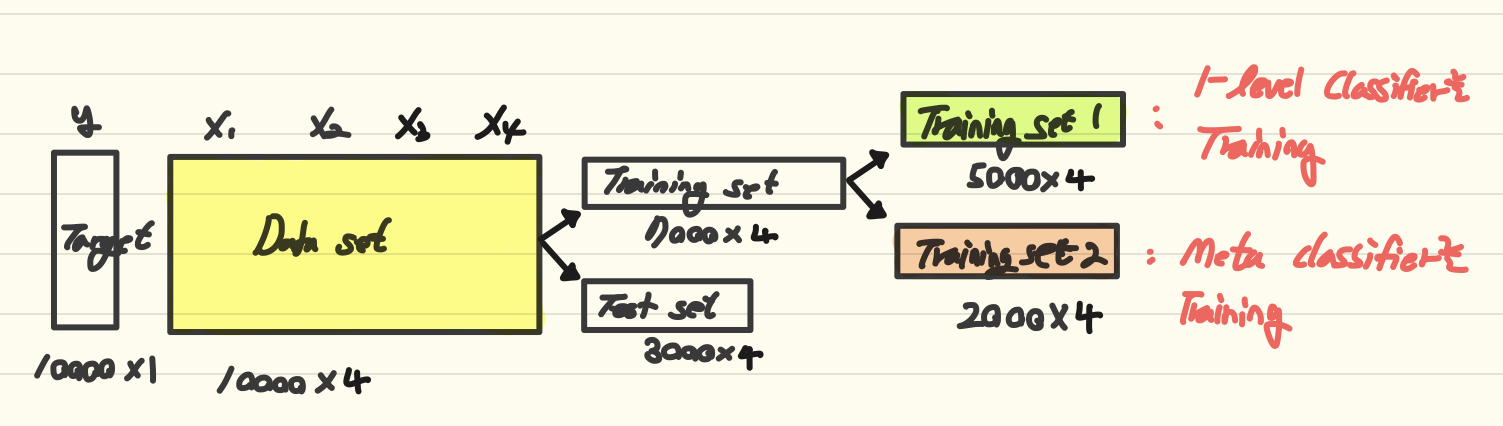
- Stacking 훈련 과정
Training Set을 두 세트로 분할 ( For Weak Learners / For Meta Learner)
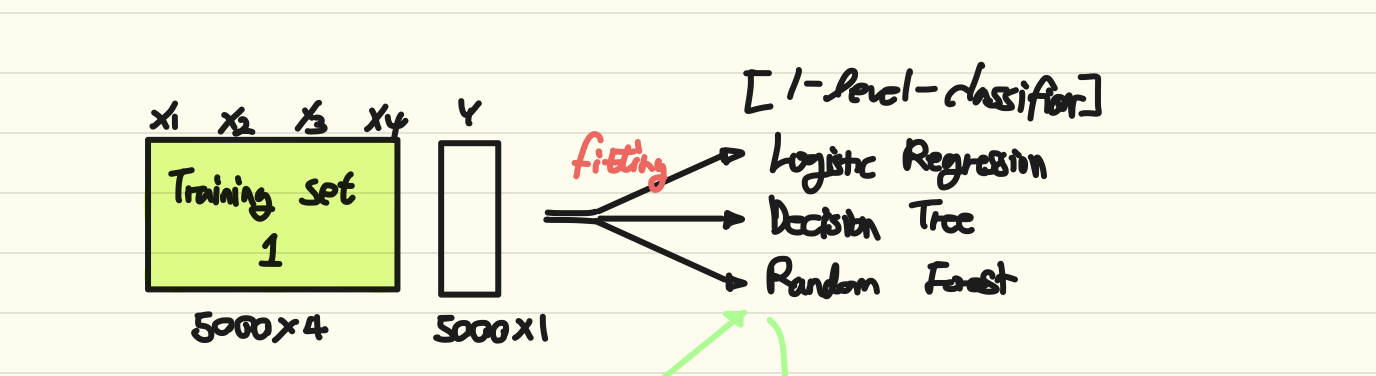
Weak Learner들을 각각 Training set 1을 활용하여 학습
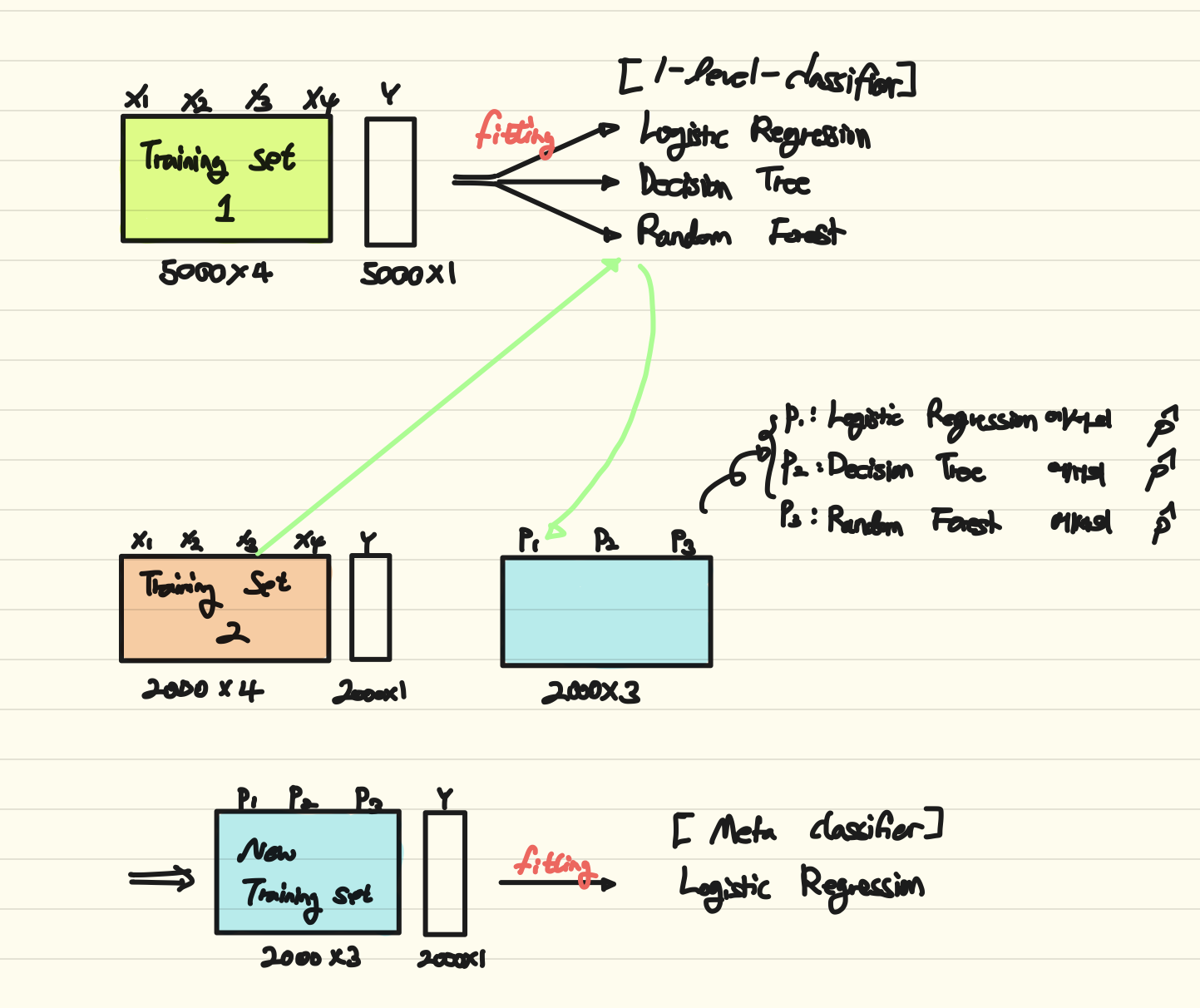
Training Set 2를 학습된 Weak Learner들의 prediction 값을 input으로 해서 Meta Learner(=Blender)를 학습
References
핸즈온 머신러닝
INEED COFFEE님의 블로그
tyami’s study blog
ITT’s tech-blog
이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)

